MIT S081 Lab 2: System Call
[mit6.s081] 笔记 Lab2: System calls | 系统调用MIT 操作系统课程 Lab 代码笔记第 - 掘金
一些前置知识:
宏内核vs微内核
一种可能是整个操作系统都驻留在内核中,这样所有系统调用的实现都以管理模式运行。这种组织被称为宏内核(monolithic kernel)。 为了降低内核出错的风险,操作系统设计者可以最大限度地减少在管理模式下运行的操作系统代码量,并在用户模式下执行大部分操作系统。这种内核组织被称为微内核(microkernel)。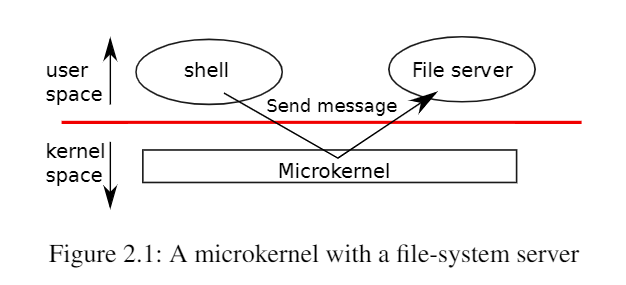
进程概述
地址空间
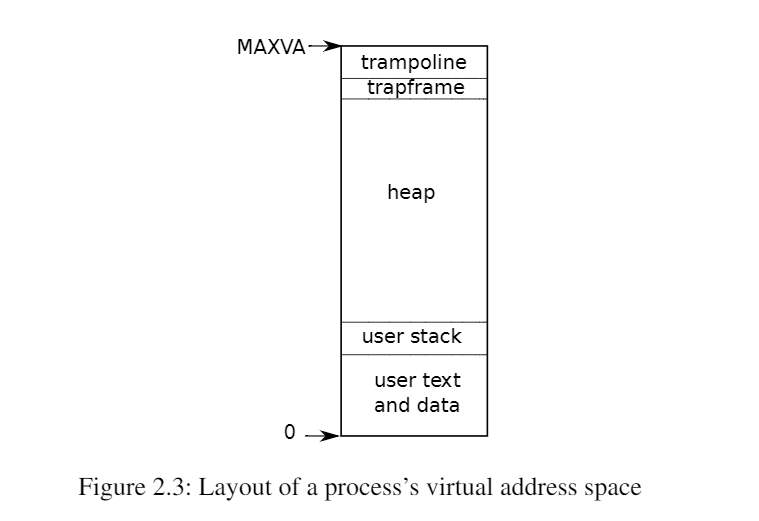 Xv6为每个进程维护一个单独的页表,定义了该进程的地址空间。如图2.3所示,以虚拟内存地址0开始的进程的用户内存地址空间。首先是指令,然后是全局变量,然后是栈区,最后是一个堆区域(用于
Xv6为每个进程维护一个单独的页表,定义了该进程的地址空间。如图2.3所示,以虚拟内存地址0开始的进程的用户内存地址空间。首先是指令,然后是全局变量,然后是栈区,最后是一个堆区域(用于malloc)以供进程根据需要进行扩展。有许多因素限制了进程地址空间的最大范围: RISC-V上的指针有64位宽;硬件在页表中查找虚拟地址时只使用低39位;xv6只使用这39位中的38位。因此,最大地址是2^38-1=0x3fffffffff,即MAXVA(定义在**kernel/riscv.h**:348)。在地址空间的顶部,xv6为trampoline(用于在用户和内核之间切换)和映射进程切换到内核的trapframe分别保留了一个页面,正如我们将在第4章中解释的那样。
每个进程都有一个执行线程(或简称线程)来执行进程的指令。一个线程可以挂起并且稍后再恢复。==为了透明地在进程之间切换,内核挂起当前运行的线程,并恢复另一个进程的线程==。线程的大部分状态(本地变量、函数调用返回地址)存储在线程的栈区上。每个进程有两个栈区:一个用户栈区和一个内核栈区(p->kstack)。==当进程执行用户指令时,只有它的用户栈在使用,它的内核栈是空的。当进程进入内核(由于系统调用或中断)时,内核代码在进程的内核堆栈上执行;当一个进程在内核中时,它的用户堆栈仍然包含保存的数据,只是不处于活动状态==。进程的线程在主动使用它的用户栈和内核栈之间交替。内核栈是独立的(并且不受用户代码的保护),因此即使一个进程破坏了它的用户栈,内核依然可以正常运行。
代码
加载程序将xv6内核加载到物理地址为0x80000000的内存中。它将内核放在0x80000000而不是0x0的原因是地址范围0x0:0x80000000包含I/O设备。
# qemu -kernel loads the kernel at 0x80000000
# and causes each CPU to jump there.
# kernel.ld causes the following code to
# be placed at 0x80000000.
.section .text
.global _entry
_entry:
# set up a stack for C.
# stack0 is declared in start.c,
# with a 4096-byte stack per CPU.
# sp = stack0 + (hartid * 4096)
la sp, stack0
li a0, 1024*4
csrr a1, mhartid
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
# jump to start() in start.c
call start
spin:
j spin用户代码将exec需要的参数放在寄存器a0和a1中,并将系统调用号放在a7中。系统调用号与syscalls数组中的条目相匹配,syscalls数组是一个函数指针表(kernel/syscall.c:108)。ecall指令陷入(trap)到内核中,执行uservec、usertrap和syscall,和我们之前看到的一样。
syscall(kernel/syscall.c:133)从陷阱帧(trapframe)中保存的a7中检索系统调用号(p->trapframe->a7),并 用它索引到syscalls中,对于第一次系统调用,a7中的内容是SYS_exec(kernel/syscall. h:8),导致了对系统调用接口函数sys_exec的调用。
当系统调用接口函数返回时,syscall将其返回值记录在p->trapframe->a0中。这将导致原始用户空间对exec()的调用返回该值,因为RISC-V上的C调用约定将返回值放在a0中。系统调用通常返回负数表示错误,返回零或正数表示成功。如果系统调用号无效,syscall打印错误并返回-1。
System call tracing (moderate)
步骤
- Add $U/trace to UPROGS in Makefile
- add a prototype for the system call to user/user.h,
int trace(int);此时可运行make qemu,会报错undefined reference to trace
- a stub to user/usys.pl.
entry("trace");至此,可以运行make qemu,Makefile会调用usys.pl并生成usys.S(汇编文件)此时trace 32 grep hello README会报错,因为还没有设置系统调用。
- and a syscall number to kernel/syscall.h.
#define SYS_trace 22- Add prototype in kernel/syscall.c,另外在函数中添加
extern uint64 sys_trace(void);static uint64 (*syscalls[])(void){
......
......
[SYS_trace] sys_trace
}- Add a sys_trace() function in kernel/sysproc.c
sys_trace(void)
{
int mask;
if(argint(0, &mask) < 0)
//获取第一个参数,对于trace而言,获得掩码
return -1;
}观察syscall.c中函数
argint用于将第n个参数复制到ip。
int
argint(int n, int *ip)
{
*ip = argraw(n);
return 0;
}考虑syscall函数,每一个系统调用都会调用此函数,可用于产生trace的输出。
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
//可添加输出语句以用于调试
printf("%d: syscall%s->%d\n",p->pid,syscall_names[num-1],p->trapframe->a0);
//
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}添加print语句,按照格式打印进程号、函数名等 完成后make qemu会产生如此输出
xv6 kernel is booting
hart 1 starting
hart 2 starting
1: syscallexec->36
1: syscallopen->2192
1: syscalldup->0
1: syscalldup->0
1: syscallwrite->1
i1: syscallwrite->1
n1: syscallwrite->1
i1: syscallwrite->1
t1: syscallwrite->1
:1: syscallwrite->1
1: syscallwrite->1
s1: syscallwrite->1
t1: syscallwrite->1
a1: syscallwrite->1
r1: syscallwrite->1
t1: syscallwrite->1
i1: syscallwrite->1
n1: syscallwrite->1
g1: syscallwrite->1
1: syscallwrite->1
s1: syscallwrite->1
h1: syscallwrite->1此时注意到mask需要在syscall和sys_trace两个函数中出现,则有考虑修改proc结构体来产生mask值用于联系二者。顺便记得在fork中将子进程和父进程的mask传递。 //寄存器a0_存放的是函数返回值
struct proc {
struct spinlock lock;
...
...
int mask;//trace_mask
};int fork(){
//copy trace_mask
np->mask=p->mask;
} void
syscall(void)
{
int trace_mask=p->mask;
if(trace_mask>>num==1)
{
printf("%d: syscall%s->%d\n",p->pid,syscall_names[num-1],p->trapframe->a0);
}
}
```kernel/sysproc.c
uint64
sys_trace(void)
{
int mask;
if(argint(0, &mask) < 0)
return -1;
struct proc* p=myproc();
p->mask=mask;
return 0;
}完成后可以尝试运行指令trace 2147483647 grep hello README 输出为
$ trace 32 grep hello README
3: syscallread->3
3: syscallread->3
3: syscallread->3
3: syscallread->3注意考虑进程清除时reset一下mask值,以防未调用trace时也追踪函数。
解决问题
debug的时候发现trace的调用一直没有出来,第二个测试指令的输出一直是这样
$ trace 2147483647 grep hello README
3: syscall exec->12240
3: syscall open->12240
3: syscall read->3
3: syscall read->3
3: syscall read->3
3: syscall read->3
3: syscall close->3
3: syscall exit->0
$ QEMU: Terminated问题有两个,第一个是trace不出现,第二个是read的返回值不对。两个问题都是同一个问题 经debug,发现在systemcall函数执行时trace_mask的值一直是0,当然没办法追踪。在函数里发现是顺序问题,给mask赋值是在sys_trace中。所以给进程里的mask赋值和掩码的位运算一定要放在函数调用之后。
num:22,trace_mask:0调整顺序后如下 寄存器a7_存放的是系统调用号
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
int trace_mask=p->mask;
if((trace_mask>>num)&1)
{
printf("%d: syscall %s->%d\n",p->pid,syscall_names[num-1],p->trapframe->a0);
}
}Sysinfo (moderate)
基本步骤同上一个实验,添加原型等不再赘述
struct sysinfo {
uint64 freemem; // amount of free memory (bytes)
uint64 nproc; // number of process
};实验要求是将一个sysinfo结构体拷贝到用户态,然后添加两个函数读取sysinfo里的两个成员。
1、在内核中实现读取空闲内存
进入kernel/defs.h内核头文件中添加声明
// kalloc.c
void* kalloc(void);
void kfree(void *);
void kinit(void);
uint64 count_free_mem(void); //here进入kernel/kalloc.c实现函数.
uint64
count_free_mem(void)
{
acquire(&kmem.lock); // 必须先锁内存管理结构,防止竞态条件出现
// 统计空闲页数,乘上页大小 PGSIZE 就是空闲的内存字节数
uint64 mem_bytes = 0;
struct run *r = kmem.freelist;
while(r){
mem_bytes += PGSIZE;
r = r->next;
}
release(&kmem.lock);
return mem_bytes;
}常见的记录空闲页的方法有:空闲表法、空闲链表法、位示图法(位图法)、成组链接法。这里 xv6 采用的是空闲链表法。
2、在内核中实现读取空闲进程
同样进入kernel/defs.h内核头文件中添加声明
// proc.c
int cpuid(void);
void exit(int);
......
int either_copyin(void *dst, int user_src, uint64 src, uint64 len);
void procdump(void);
uint64 count_proc(void); //here进入kernel/proc.c实现函数
uint64
count_proc(void)
{
uint64 cnt = 0;
for(struct proc *p = proc; p < &proc[NPROC]; p++) {
// acquire(&p->lock);
// 不需要锁进程 proc 结构,因为我们只需要读取进程列表,不需要写
if(p->state != UNUSED) { // 不是 UNUSED 的进程位,就是已经分配的
cnt++;
}
}
return cnt;
}3、在sys_file中设置sys_sysinfo()函数,拷贝到用户态。
提示告诉我们要使用copyout() - sysinfo needs to copy a struct sysinfo back to user space; see sys_fstat() (kernel/sysfile.c) and filestat() (kernel/file.c) for examples of how to do that using copyout().
int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)从内核空间向用户空间拷贝数据 // 从src拷贝len长度的字节到pagetable页表的dstva位置处 / / 成功时返回0,错误时返回-1
注意:此时kernel/sysfile.c中未include本题提供的sysinfo.h(定义sysinfo结构体的文件),需要手动添加。
uint64
sys_sysinfo(void)
{
struct proc *p = myproc();
struct sysinfo info;
//为info赋值
info.freemem=count_free_mem();
info.nproc=count_proc();
uint64 addr;
if(argaddr(0,&addr)<0)
return -1;
if(copyout(p->pagetable, addr, (char*)&info, sizeof(info)) < 0 )
return -1;
return 0;
}其他
经调试,sysinfo(&info) 这个语句会产生系统调用
void
testcall() {
struct sysinfo info;
if (sysinfo(&info) < 0) {
printf("FAIL: sysinfo failed\n");
exit(1);
}
if (sysinfo((struct sysinfo *) 0xeaeb0b5b00002f5e) != 0xffffffffffffffff) {
printf("FAIL: sysinfo succeeded with bad argument\n");
exit(1);
}
}问题
1、如系统调用,open函数在被使用时,用户态切换到核心态,并根据中断向量号(是不是)类似这种,跳转到相应的程序,(syscall.c里面的函数指针实现的)。
#define SYS_fork 1
#define SYS_exit 2
#define SYS_wait 3
#define SYS_pipe 4我的问题是调用open的时候哪部分软件,(在哪个文件能看到),在完成这个把对应的向量号发送的任务。
A:注意到这个usys文件。
print "# generated by usys.pl - do not edit\n";
print "#include \"kernel/syscall.h\"\n";
sub entry {
my $name = shift;
print ".global $name\n";
print "${name}:\n";
print " li a7, SYS_${name}\n";
print " ecall\n";
print " ret\n";
}
entry("fork");
entry("exit");
entry("wait");
...
...这里的entry就是系统调用的入口。 所以顺序是user.h提供用户接口,然后从usys.pl进入内核态,接着在内核中syscall.c中函数指针调用相应的函数,函数实现在sysproc.c或者sysfile.c中